Liviu Pirvan
Super-Resolution using Coordinate-Based Neural Networks
Preliminaries
This is a quick post exploring a process of upscaling images using neural nets with no training data other than the downscaled image itself.
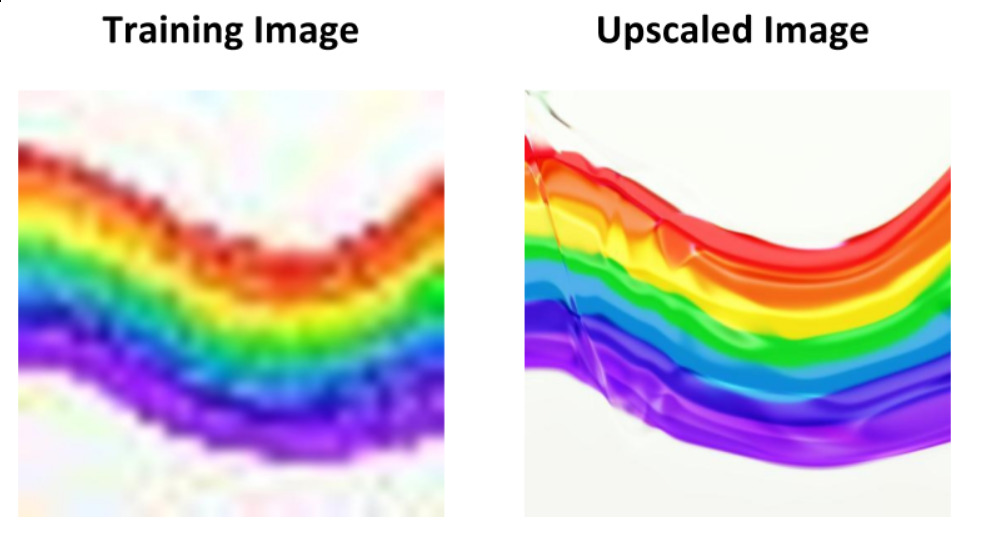 Figure 1: The image was upscaled from 32x32 to 1024x1024, but one may as well see it as denoising the way it is presented above.
Figure 1: The image was upscaled from 32x32 to 1024x1024, but one may as well see it as denoising the way it is presented above.
The idea is to train a network $f: \mathbb{R}^2 \to \mathbb{R}^3$ to map from pixel coordinates to R, G, B values:
That is, given any 2 pixel coordinates, the network will output a colour for that pixel. The implications of having such a network is that one can then process colour values for arbitrarily large images by simply feeding the model a large variety of pixel coordinates.
Related work
The idea arose from looking at the samples on otoro.net, and wanting to simplify the system to only upscale images, rather than generate new large images. After simplifying the model, the core idea is the same as the one used by Andrej Karpathy here and by Thomas Schenker here. Further, a similar network was introduced by Kenneth O. Stanley in 2007 under the name of CPPN. However, I have not seen the network used for upscaling existing images, so I decided to give it a try and see how it performs.
Code
The code I used for this work may be found in the format of a Jupyter Notebook here with additional comments to clarify each of the code sections. The network was implemented in TensorFlow, and the program is about 50 lines of code.
Upscaling
While training, the network uses a small image ($32\times 32$ or $64\times 64$) and learns to map each pixel coordinate to a colour based on the image itself. Therefore, in the training process, the model only learns how to replicate the image provided. Once the training is complete, the model can be used as a function that outputs colour for any 2 coordinates provided:
- For coordinates saw during the training process, the network will output what it learned during the process;
- and for new coordinates, the network will estimate some plausible value to fill in.
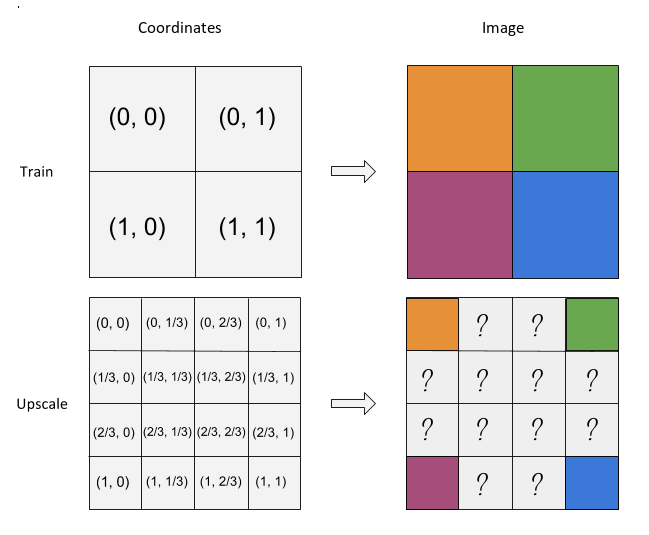 Figure 2: On the first row, the training process uses a 2x2 image and the model learns to map from pairs of coordinates to pixel colours. On the second row, the network already knows how to map some of the coordinates (the corners), but it is unpredictable what the network will output for the other coordinate values in the 4x4 image.
Figure 2: On the first row, the training process uses a 2x2 image and the model learns to map from pairs of coordinates to pixel colours. On the second row, the network already knows how to map some of the coordinates (the corners), but it is unpredictable what the network will output for the other coordinate values in the 4x4 image.
Note that the coordinates are normalised between 0 and 1 such that the upper left corner is $(0,0)$. However, different ways of normalising may provide different results – for instance, setting the upper left corner to $(-1, 1)$ and the centre of the image to $(0,0)$ would ensure that the inputs are roughly centred around $0$. Further, one may standardise inputs such that batches have unit-variance, and potentially obtain different results.
For some lower level details about the exact network architecture, weight initialisation, and other hyperparameters, please check out the notebook where you can also clone the repository and upscale your own images.
Results
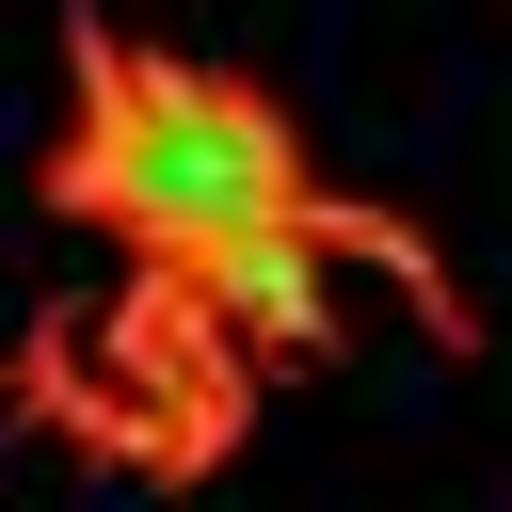
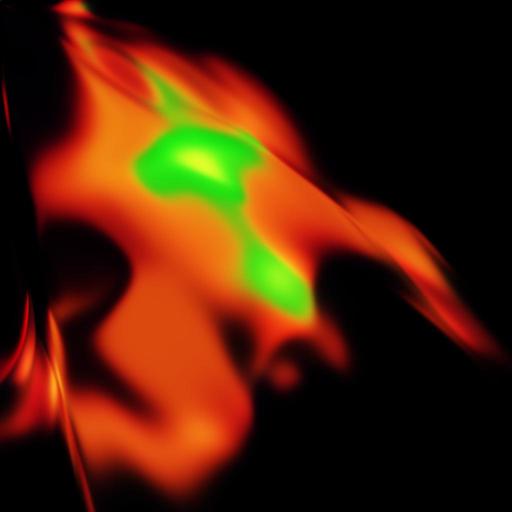
Some quick results I obtained can be observed in the table below. Please note that all samples are resized to $512\times 512$ but the original sizes are $1024\times 1024$ for the generated image, $32\times 32$ or $64\times 64$ for the training sample, and varying size for the original images.
Clicking on an image opens a slightly enlarged version.
| Training Sample | Network Output | Original Image |
|---|---|---|
 |
 |
 |
| Source | ||
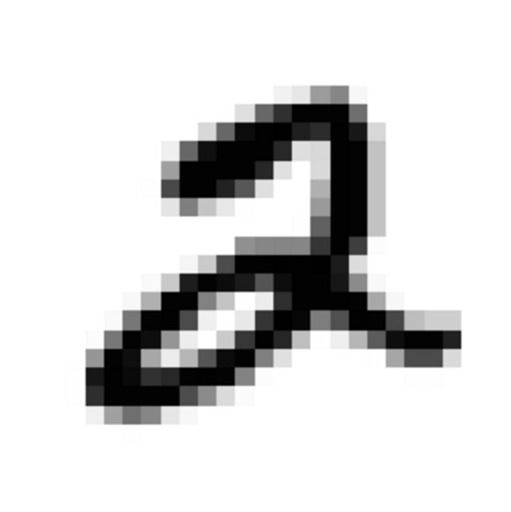 |
 |
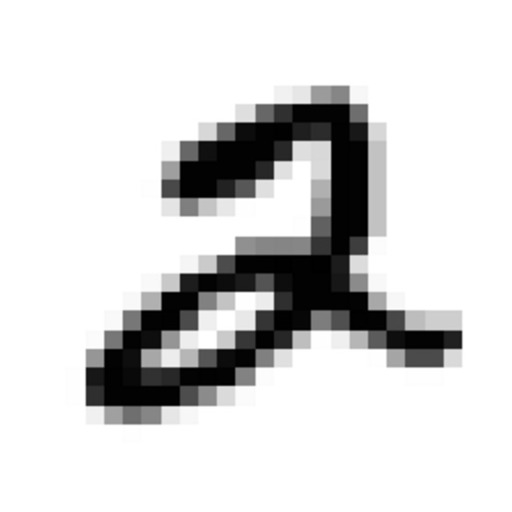 |
| Bit similar to these | MNIST digit | |
 |
 |
 |
| Source | ||
 |
 |
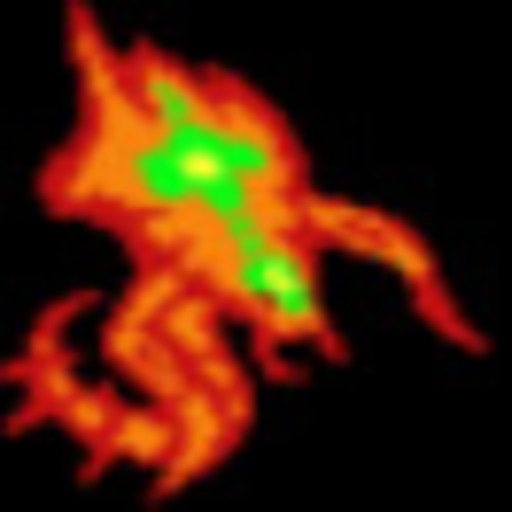 |
| StarCraft: BW Hydralisk | ||
 |
 |
 |
| Source | ||
 |
 |
 |
| Picasso’s “Looking for my Betty Ross” | ||
 |
 |
No original image, as this was just uniformly generated noise, so all credit goes to the network. |
 |
 |
 |
| Source | ||
 |
 |
 |
| Source | ||
 |
 |
 |
 |
 |
 |
 |
 |
 |
{kind=link}
No quantitative analysis has been performed yet, but it can be observed that details and texture are typically lost, while high-contrast regions seem to be well preserved after processing.
Conclusion
I believe the results look interesting and are worth investigating further. Importantly, it would be beneficial if one would not need to retrain the network for every image, but rather train only one autoencoder network on an entire dataset. Further, none of the networks were trained to full capacity to learn the mapping properly (i.e. MSE $\not\approx 0$ on the training set) even if overfitting may be desirable, so longer training time and more expressive networks may also help.
Other possible directions include focusing on denoising, analysing the linearity of networks as functions of inputs, considering regions instead of single pixel coordinates, quantitatively comparing upscaling capabilities, exploring potential from an artistic perspective, and packaging a web interface.